Ga naar de inhoud
Ga naar de inhoud Open antwoorden vormen vaak de meest waardevolle feedback. Maar hoe verwerk je die data? Weet je zeker dat je er alle inzichten uithaalt? Het verwerken van open antwoorden is namelijk een enorme klus die niet altijd even secuur en grondig wordt gedaan. Waardevolle inzichten kunnen hierdoor verloren gaan. Bij MWM2 hebben we de techniek en kennis om relatief snel heel veel meer inzichten uit jouw data te halen. Dit heet MWM2 Topic Modeling.
Het probleem van handmatig coderen
Je hebt het vast wel eens gedaan: coderen. Open antwoorden turven in een Excelbestand. Van tevoren bedenk je categorieën en probeer je elk antwoord in een hokje te plaatsen zodat je gestructureerde en meetbare data overhoudt. Een goed idee, maar niet erg efficiënt en accuraat. Als je grote datasets hebt van een paar duizend waarnemingen is het vrijwel ondoenlijk om dit nog handmatig te coderen. Het gevolg is dat de meeste van ons na een paar honderd reacties trucjes gaan verzinnen om zo snel mogelijk door de rest van de open antwoorden heen te gaan. Of we besteden het uit aan een werkstudent; wat ook de kwaliteit niet altijd ten goede komt.
Wat is Topic Modeling
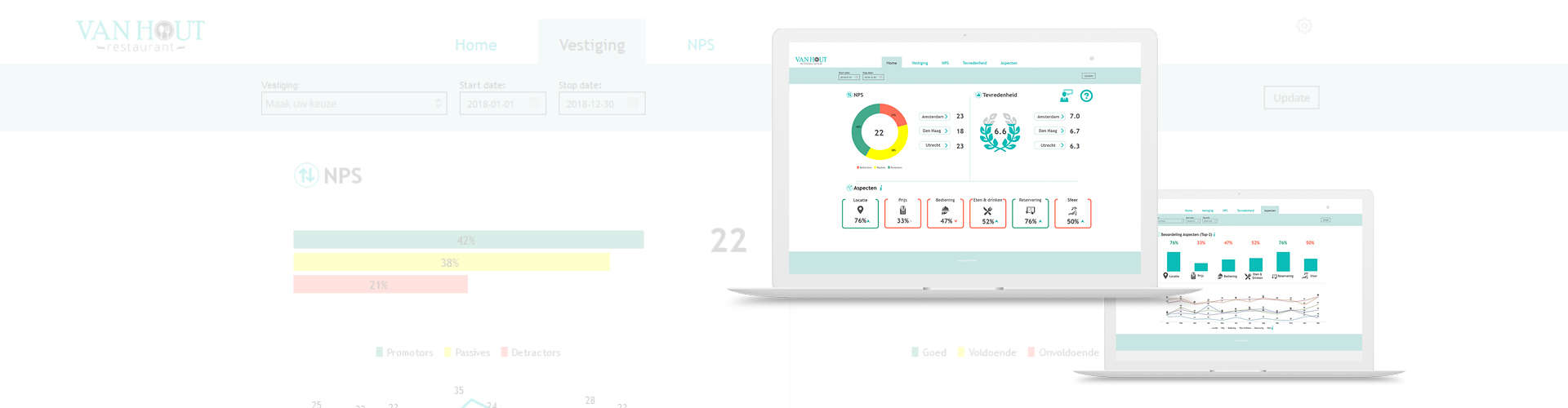
Om iets te doen aan dit inefficiënte en onnauwkeurige proces van turven zijn we bij MWM2 jaren geleden begonnen met het semiautomatisch coderen van open antwoorden. Dit heeft uiteindelijk geresulteerd in onze Topic Modeling techniek. Topic Modeling is een machine waar je een grote dataset met tekstdata instopt. De machine schoont de data op en gaat op zoek naar patronen in de data. Gevonden patronen vertegenwoordigen thema’s die veel in de data voorkomen. Als resultaat krijg je deze thema’s terug en kan je hier op inzoomen.
Mensenwerk maar wel veel sneller
Topic Modeling blijft echter deels mensenwerk. Je hebt een specialist nodig die bepaalt op welke manier de data moet worden opgeschoond en interpreteert wat een relevant aantal thema’s is en wat die betekenen. Maar waar het verwerken van 10.000 open antwoorden jou als marktonderzoeker al gauw een week werk kost, kunnen wij met onze Topic Modeling techniek in slechts 8 uur alle waardevolle inzichten voor je ophalen.
Ook voor telefoontranscripten en data uit social media
Met MWM2 Topic Modeling halen wij inzichten uit vrijwel alle ongestructureerde tekstdata. Denk bijvoorbeeld aan transcripten van telefoongesprekken die worden opgeslagen, open feedback op websites, social data, data van langlopende onderzoeken, etc. Vaak gaat het hier om datasets van vele tienduizenden records die wij razendsnel kunnen verwerken.
Topic Modeling biedt kansen
Met MWM2 Topic Modeling krijg je een kans om te leren van de open feedback die klanten met je delen (op welke manier dan ook). Het is een manier om snel antwoord te krijgen op vragen als ‘wat vinden mijn klanten belangrijk?’, ‘waar moet ik over communiceren?’, ‘zijn er knelpunten in mijn klantreizen?’, etc. Dus heb je ergens een berg tekstdata liggen? Laat dit dan niet op de plank liggen. Besteed je tijd efficiënt en laat ons je data verwerken.